How this blog is made, Archivarix, some PHP and Hugo
Last updated: Dec 2, 2023
The legacy of my blog, recover with Archivarix
For me this year was like a rollercoaster, and I forget my blog was hosted on a very old Online.net Dedibox server, now called Scaleway. This server was in a process to be decomission and I missed the 3 emails annoncing the end of my services. Then Online.net decided that it was a good idea to also delete the backups spaces attached to these machines. To sumup I loose my blog and the recent backups. But I wanted to keep it and a least serve the existing content that was linked on search engines and other websites. I looked on the wayback machine and my blog was in it. I found a cool all-in-one service to restore an entire website from the Wayback machine called Archivarix, the cost was arround 10€.
I recovered a 300MB zip archive with a lot of content, some images are missing but all the articles was there.
Running the Archivarix Loader
Archivarix loader is a single php file using a sqlite database with all
your urls inside and the content is stored as files in www/.content.EZtzwPjb/binary/.
Each time a HTTP request is process, the script look in the database for
a matching url and serve the content linked to it. This mini cms is
license under GPL, and I put a copy here.
With docker
You need PHP and SQLite extension, the PHP docker image already contains that. I have done a small docker-compose for running archivarix.
Simple as run docker compose up.
With Yunohost
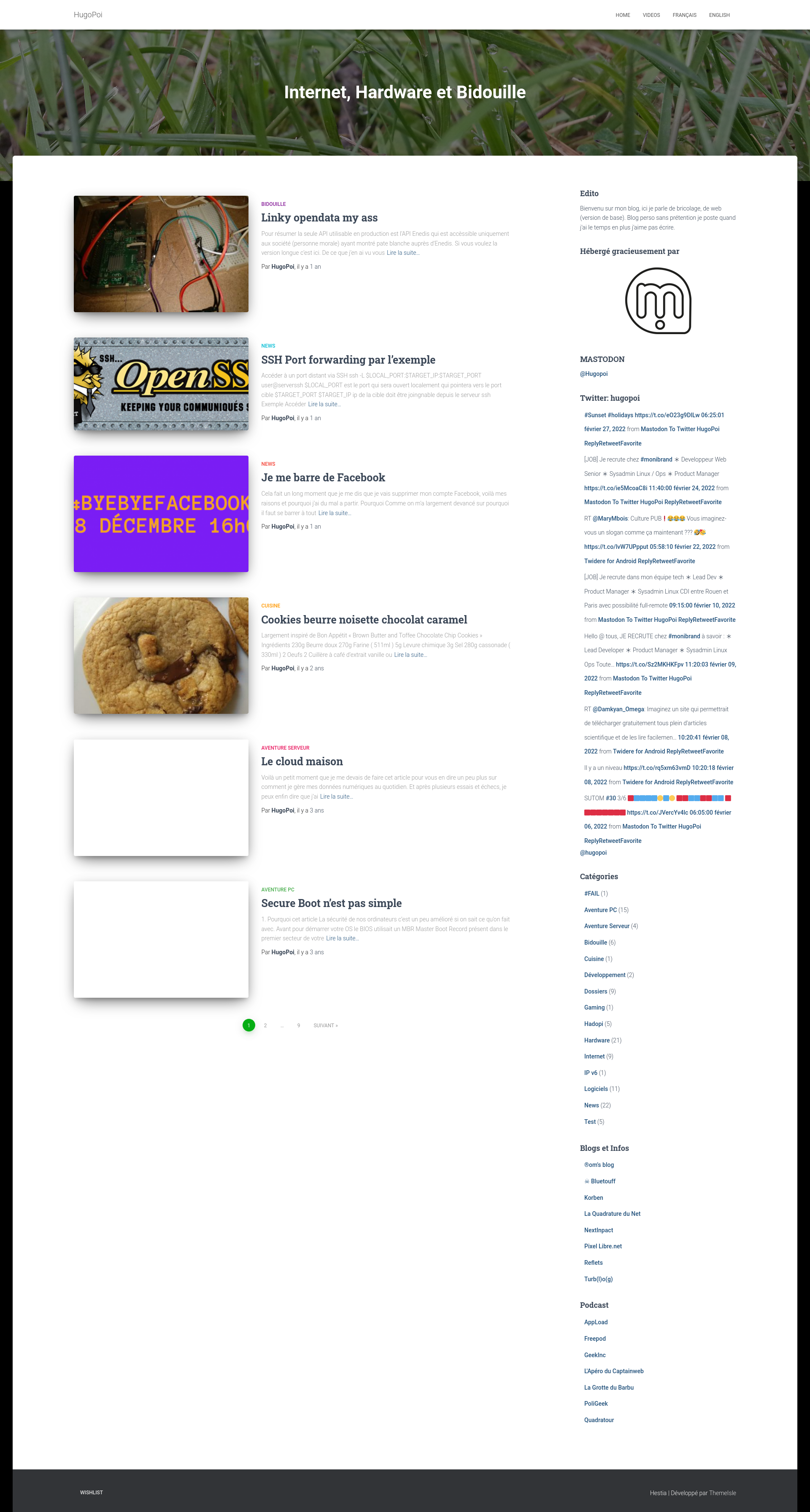
I’m mainly self-hosted with the Yunohost project, those next steps show you how to easily add a small php inside your Yunohost instance.
-
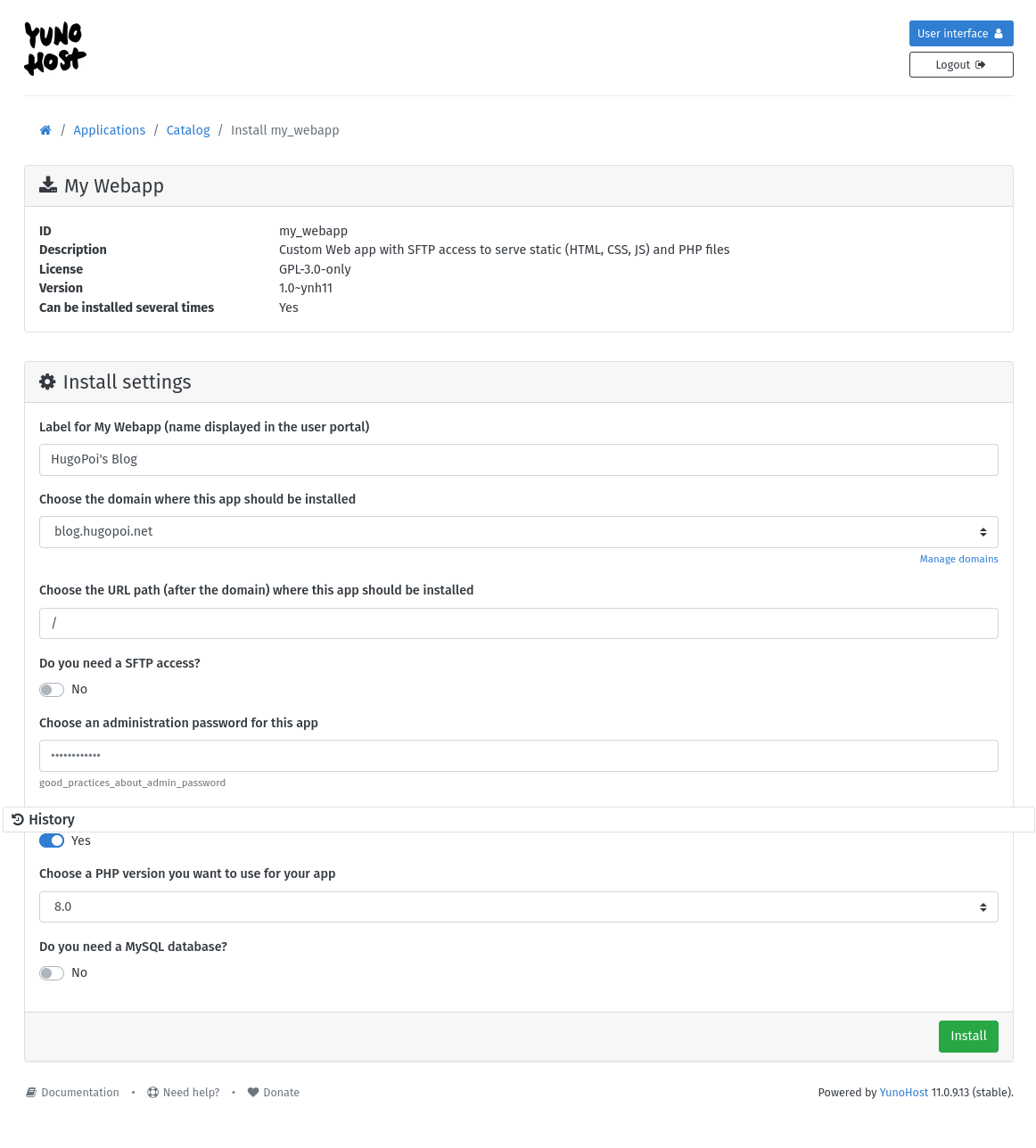
Install the application
My Webappinside the yunohost admin panel
TODO -
Fill the setup form
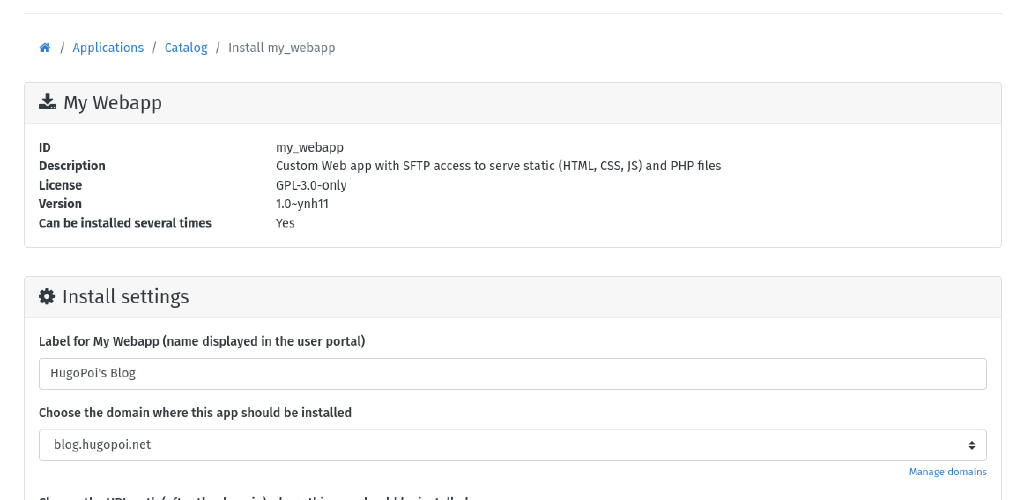
TODO -
You have an empty app inside
/var/www/my_webapp/www/
TODO -
You need to copy your files, I use rsync with the yunohost admin account
rsync -rlgoD --checksum --verbose www/ admin@home.hugopoi.net:/var/www/my_webapp/www/ -
Then you might need to
chmod 664 /var/www/my_webapp/www/.content.*/structure.*, Archivarix required some write access on the sqlite files.

Modding Archivarix Loader
Fixing Wordpress version missing files
The homepage was looking good but some wordpress css and javascript assets were missing. Wordpress use a query params ?ver=.
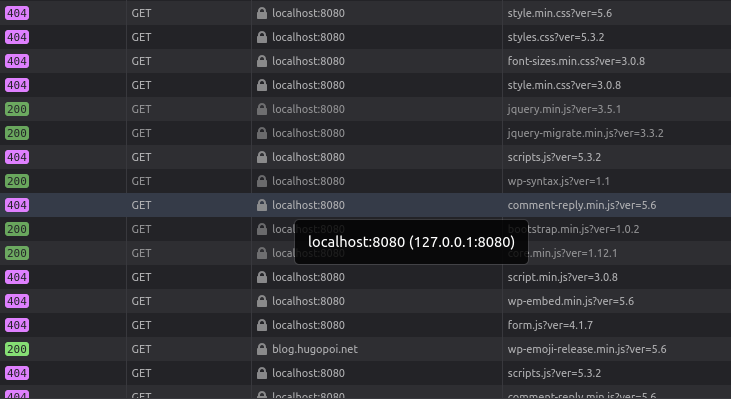
?ver= query params with Archivarix
So I code a little function to load any version available for a given url. And I take the most recent one.
Cleaning existing pages
After successfully running my backuped blog, I wanted to mod some content.
- Replace the twitter widget
- Replace the hoster widget
- Add a legacy warning for visitor to redirect to the new blog
Archivarix has a ARCHIVARIX_INCLUDE_CUSTOM relying
on regular expression to replace content but I needed a more precise approach. I used the PHP XML extension which has a DOM parser buit in and can
parse HTML pages.
The new blog with Hugo
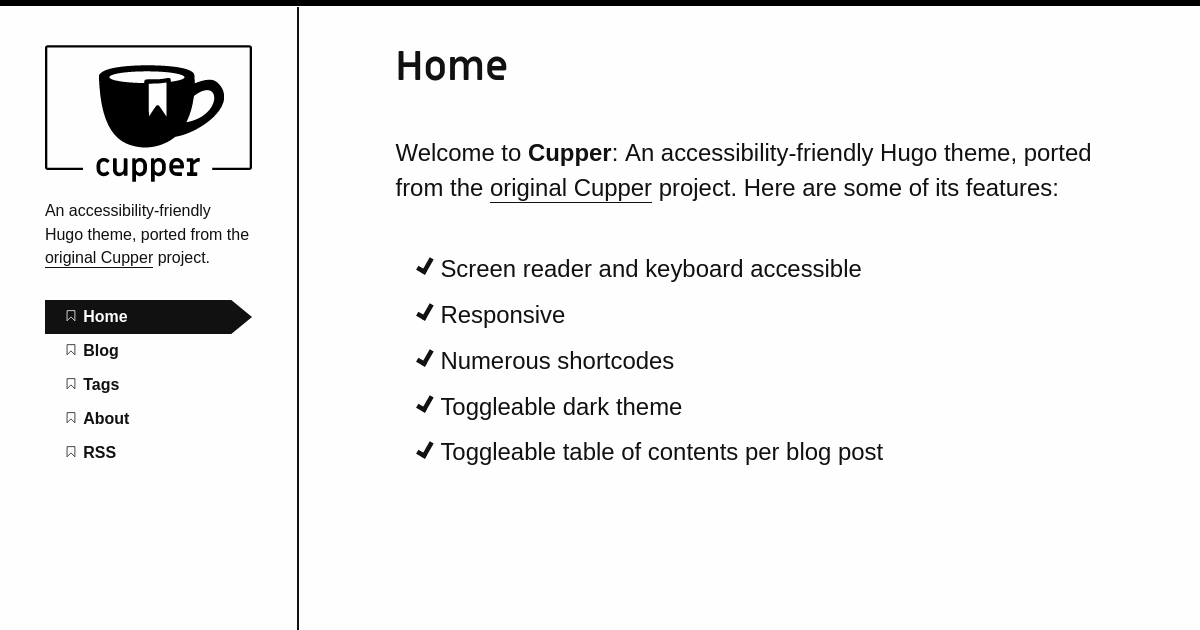
I wanted simple markdown that generate static HTML, this why I choose Hugo for my blog.
-
First I add a new directory called
v2next to the legacy blog. -
Then you launch
hugo new site v2this will generate the folder tree needed. -
I choose the Cupper theme

Cupper Theme for Hugo -
I add the Cupper theme with
git submodule add https://github.com/zwbetz-gh/cupper-hugo-theme.git themes/cupper-hugo-theme -
Add some custom css
-
Add some config in
config.toml -
I also upgrade prism.js for code highlight in theme itself
-
I add favicon and logo
-
Then I need to build with
hugo -
Deploy with rsync in yunohost
-
I add a CORS header in nginx config of my Gitea to allow fetching code inside
<pre>html tagsrewrite ^/gitea$ /gitea/ permanent; location /gitea/ { proxy_pass http://localhost:6000/; proxy_set_header Host $host; proxy_buffering off; client_max_body_size 200M; proxy_set_header X-Real-IP $remote_addr; # Include SSOWAT user panel. include conf.d/yunohost_panel.conf.inc; add_header 'Vary' 'Origin'; # Add CORS header for loading code in pre html tags if ($http_origin ~* "^(http://localhost:1313|https://blog.hugopoi.net)$") { add_header Access-Control-Allow-Origin "$http_origin"; } }
Moooore to come !