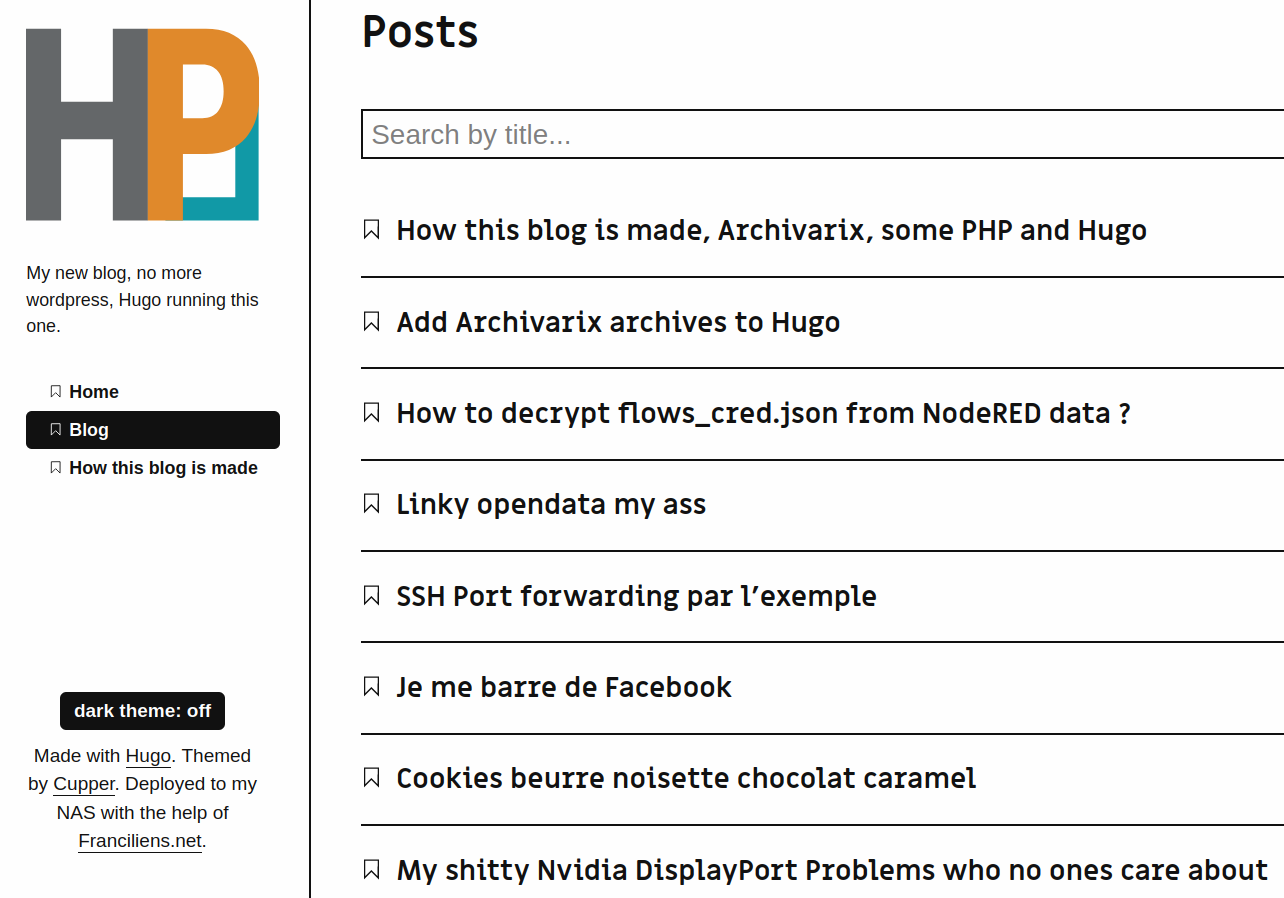
Add Archivarix archives to Hugo
Last updated: Dec 21, 2022
I want to add all my old articles to the Hugo posts list page.
Let’s write some code.
- I can use the Archivarix sitemap as source
- Or I can use the sqlite database as source
- I want to add all the canonical pages to the list
- Sorted by reverse date of publication
- With the title
First, I discover that GoHugo handle override over files, if you have a file
in /themes/<THEME>/static/js/jquery.min.js, you can override it with a
file in /static/js/jquery.min.js. So I think I don’t need a custom
theme, so let’s remove that.
Proof of concept with a sitemap
-
First I change the
index.phpand add a sitemap path to enable sitemap generation in Archivarix loader. -
Generate a sitemap
wget http://localhost:8080/sitemap.xml -
Then I discover sitemap doesn’t have title in specification so it’s a dead end.
-
Place
sitemap.xmlin/data/legacyblog/sitemap.xml -
Let’s poc the change in our Hugo theme in
layouts/_default/list.html
# Will load the file and parse it
{{ range $.Site.Data.legacyblog.sitemap.url }}
<li>
<h2>
<a href="{{ .loc }}">
<svg
class="bookmark"
aria-hidden="true"
viewBox="0 0 40 50"
focusable="false"
>
<use href="#bookmark"></use>
</svg>
{{ .loc }}
</a>
</h2>
</li>
{{ end }}
I will not use this solution we can’t have title with it.
Proof of concept with webcrawl csv file
Some times ago, I develop a little web crawler or spider that can list all the urls and robot metadatas for a given website.
npm install -g hugopoi-webcrawlerhugopoi-webcrawler http://localhost:8080 --progresswill create a file calledlocalhost_urls.csv
"url","statusCode","metas.title","metas.robots","metas.canonical","metas.lang","parent.url"
"http://localhost:8080/",200,"HugoPoi – Internet, Hardware et Bidouille","max-image-preview:large",,"fr-FR",
"http://localhost:8080/v2/",200,"HugoPoi Blog",,"http://localhost:1313/v2/","en","http://localhost:8080/"
"http://localhost:8080/en/",200,"How to decrypt flows_cred.json from NodeRED data ? – HugoPoi","max-image-preview:large","http://localhost:8080/en/2021/12/28/how-to-decrypt-flows_cred-json-from-nodered-data/","en-US","http://localhost:8080/"
- Then we put this file outside of data directory as mention in the documentation of Hugo
- Mod the template with CSV parse function
<!-- Loop against csv lines -->
{{ range $i,$line := getCSV "," "./localhost_urls.csv" }}
<!-- Fill variables with columns -->
{{ $url := index $line 0 }}
{{ $title := index $line 2 }}
<!-- Skip csv head line and replytocom wordpress urls -->
{{ if and (ne $i 0) (eq (len (findRE `replytocom` $url 1)) 0)}}
<li>
<h2>
<a href="{{ $url }}">
<svg
class="bookmark"
aria-hidden="true"
viewBox="0 0 40 50"
focusable="false"
>
<use href="#bookmark"></use>
</svg>
{{ $title }}
</a>
</h2>
</li>
{{ end }}
{{ end }}
This solution is promising.

Refining the webcrawler and the theme mod
- Let’s use JSON file instead of csv
- Filter only articles urls and order them by dates
First I add --output-format json option to my webcrawler.
The usage become :
hugopoi-webcrawler https://blog.hugopoi.net/ --output-format json --progress
> crawled 499 urls. average speed: 37.32 urls/s, totalTime: 13s
Now we can handle the data with jq '. | length' blog.hugopoi.net_urls.json
Now let’s filter this file and order it.
-
Remove replytocom duplicate urls and response error urls without title
jq '. | map(select((.metas.title != null) and (.url | test("\\?replytocom") == false))) | .[].url' blog.hugopoi.net_urls.json -
Select only urls that contains a date pattern, because my wordpress urls were built with
/YYYY/MM/DD/THE_TITLEpattern.jq '. | map(select((.metas.title != null) and (.url | test("(\\?replytocom|^https://blog.hugopoi.net/v2)") == false) and (.url | test("/[0-9]{4}/[0-9]{2}/[0-9]{2}/[^/]+/$")))) | sort_by(.url) | reverse' blog.hugopoi.net_urls.json > blog.hugopoi.net_urls.filtered.json -
Remove
– HugoPoifrom the titlesjq '. | map(.metas.title |= sub(" – HugoPoi"; "")) | .[].metas.title' blog.hugopoi.net_urls.filtered.json
Now we have a proper urls data source
Override the Hugo Theme layout
We now have a data/LegacyBlogUrls.json file with all urls I want to
put in the blog posts index page.
I copied the original themes/cupper-hugo-theme/layouts/_default/list.html to layouts/_default/list.html.